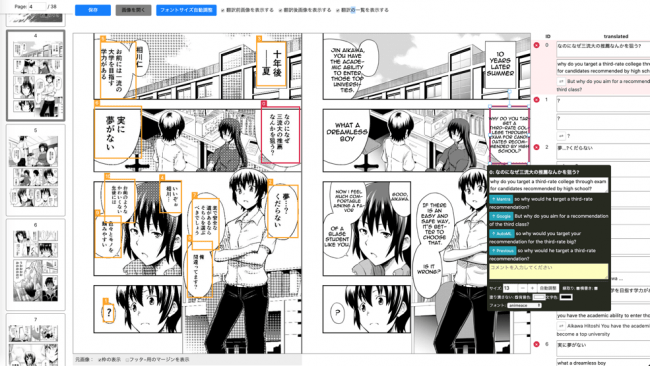
最近の自動翻訳への不満は一昔前と比べると格段に減ったように思います。私は海外記事の引用をすることが多いため自動翻訳を頻繁に使いますが、意味の理解にストレスを感じることはありません。テキストデータであればGoogle翻訳、DeepL。音声であればYoutubeの音声自動翻訳とネットを通した言語の壁はなくなりつつあります。
ただし、画像データは例外です。一般的な記事には多くありませんが、企業のリサーチをしていると構造化された図と文字がセットのJPEGがHPに張られているケースが少なくありません。英語であれば多少教養があるので読めますし、最悪Google翻訳に手で入力できるので問題はありませんが、中国語やスペイン語、フランス語で書かれていてはお手上げです。
紙であれば光学的文字認識(OCR)が広く活用されていますが、わざわざ印刷して読み取るのは手間であるのに加えて、リーズナブルに精度の良いOCRを利用することは難しいのが現状です。私が抱えるこの小さな課題は「画像データの自動翻訳」という視点で見えると、まさに大きな課題となっている業界が存在します。
それがマンガです。
日本文化の一つとして世界中に知られるようになったマンガ。私がホームステイした時も、所属していた研究室の留学生とも、最初のコミュニケーションはマンガ・アニメについてでした。文化的な橋渡しの役割を担うマンガが海外に出るときには当然のことながら翻訳されます。
紙に描く場合はもちろんですが、PCで描く場合でもエンコードせずにセリフ・効果音のレイヤーだけを別にして扱うのは不便であるため、自動翻訳するには画像データからテキストだけを読み取って翻訳することが求められます。しかし、これが難しい。
名刺や資料のようにある程度フォーマットが決まっていれば文字認識のルール作りは大変ではあるものの困難ではありません。フォント、場所、誰のセリフなのか、吹き出しの中の読む順番、マンガを正しく翻訳するために必要な情報は複雑です。

Image Credit:Mantra
そこで今回は、マンガ特化の自動翻訳を実現する「Mantra」創業者の石渡祥之佑氏に海外のマンガ市場と、マンガ特化の自動翻訳とは一体どんな技術なのかについてオンライン取材を実施しました(太字の質問はすべて筆者、回答は石渡氏)。
同社は6月8日にディープコア(DEEPCORE)、合同会社DMM.com(DMM VENTURES)、レジェンド・パートナーズ、およびエンジェル投資家らを引受先とする第三者割当増資により、合計約8,000万円の資金調達を実施しています。
マンガの海外市場について教えてください
アメリカの場合でいうと、漫画にお金を払っている人は日本の1/3程度です。人口が日本の約3倍いるので結構少ないですが、マンガファンが少ないわけではありません。海賊版で読んでいる人が多い状況です。
海外における日本マンガの売り上げは1380億円だと伺いました。かなり小さい印象です。
そうなんです。ただし海外の売り上げは伸び続けています。国内はシュリンクしてて、電子も合わせるとトントンといった感じなので、出ていかないといけない、という思いはあるにはある状況です。
海外ではマンガは紙と電子、どちらが売れているんですか
熱狂的なファンが紙で出ているものを買うケースが多いです。日本だと電子が増えきて半々くらいですが、海外での日本漫画の電子版の売り上げは少ないです。
日本の出版社が製本までのフローを開拓しているんですか、それともライセンスを運用する形ですか
今までは後者が多かったらしいです。日本の出版社の中に海外ランセンス部門があって、海外の出版社からの問い合わせに対して、契約を取り付ける。翻訳、印刷、出版は向こうの出版社がメインでやる形です。紙の場合、海外の出版社が版の開拓、在庫のコストなどリスクを負っている分、日本の出版社の取り分は8%だと言われています。

さらに取り分の8%から出版社と作家さんに分けるとなると、単価が安いマンガでは作家さんの海外に出るメリットが薄い状況と言えそうです
本当にそうだと思います。海外で出版された作家さん達にヒアリングしましたが、別に儲かったりしないと聞くことが多かったです。
この状況が変わりつつあると
全体的な流れとしては、電子版をきっかけに日本の出版社が主体となって出版するようになってきています。「MANGA+」が集英社が主体となって英語版を出しているのは良い例です。電子版だけしか出さないのならば販路の問題もなくなる。当然、ピンハネされていた部分がなくなるので、もし売れるんだったら作家さんも出版社も嬉しいですよね。最近その流れが始まりつつあると思っています。
それにMantraはどのように関わってくるのでしょうか
国内のプレイヤーが自分たちで出していきたいとなった時、今までやらなかった工数をやる必要が出てきます。例えば翻訳です。外注してクオリティーチェックするのは大変なので、それをサポートするのがMantraの技術です。
週刊連載を英語版を出そうと思うと、かなりの速度で作業をすることが求められます。翻訳会社とのデータのやり取り、スケジュール調整、修正箇所の訂正。Mantraは一週間以内にできるのを目指すワークツールも含んだプロダクトで、オペレーションが大変になるところをお手伝いしたいと考えています。
ここで気になることがあります。なぜ、Mantraは「一週間以内にできる」ことを明言するほど速度にこだわるのでしょうか?
これには海賊版サイトという大きな問題が絡んでいます。
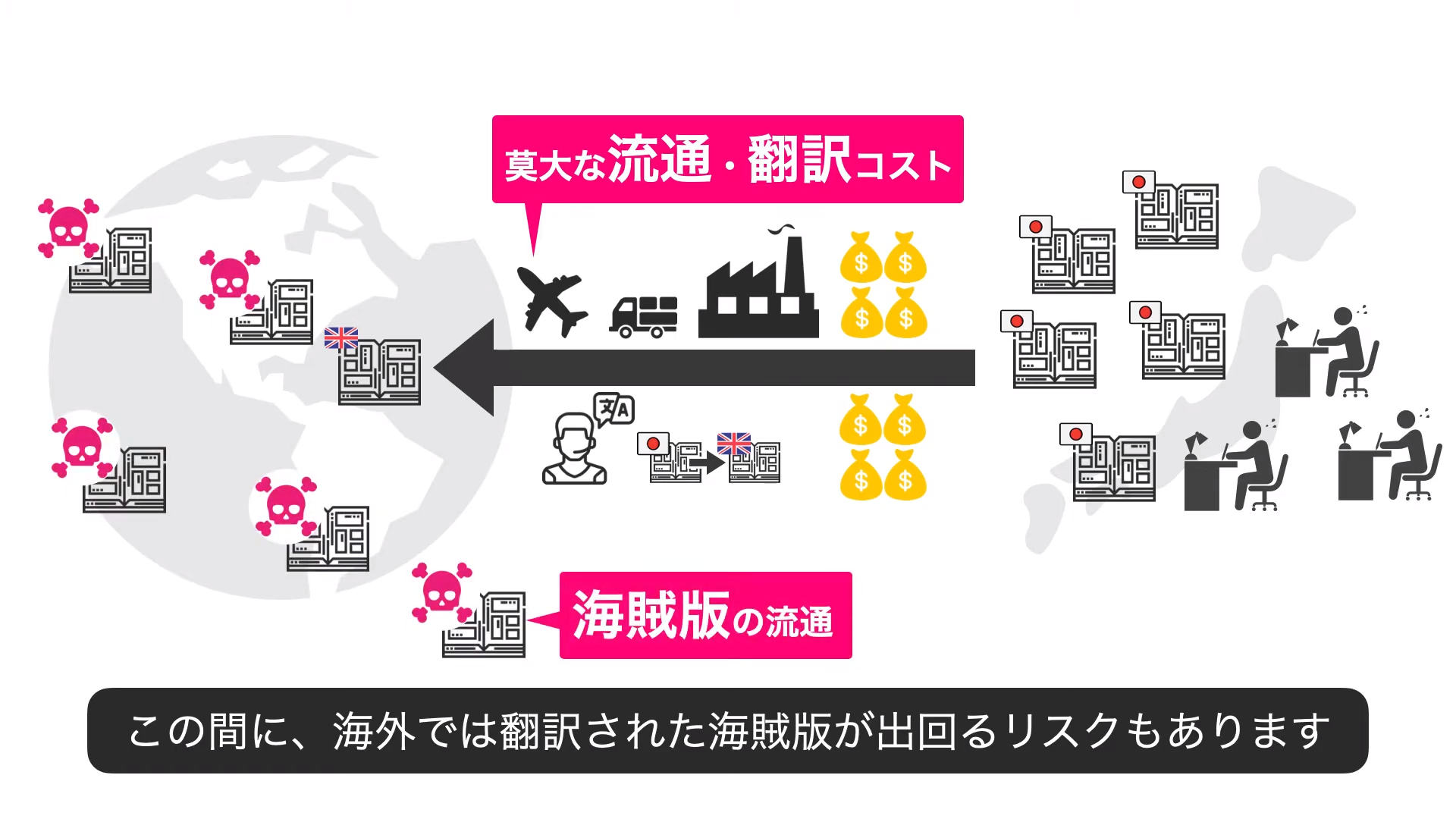
2018年「漫画村」「Anitube」「Miomio」の3つの海賊版サイトが閉鎖されました。国の知的財産戦略本部・犯罪対策閣僚会議「インターネット上の海賊版サイトに対する緊急対策」で悪質サイトとして実名を挙げられ、サイトブロッキング政策の対象となった結果です。昨年「漫画村」の運営者が逮捕されたのも記憶に新しいと思います。
特に「漫画村」は大きなサイトで、2018年3月時点の月間ユニークユーザ662.1万人、出版物流通額ベースの被害額は約3,000億円と推計されていました。ほとんどが日本国内からのアクセスであったため、国主導のサイトブロッキングで被害の大部分を防げたのは喜ばしいことです。しかし言い変われば、日本国外の被害は全く防げていないということでもあります。
当然、日本のコンテンツを扱うオンライン海賊版は世界中に存在します。経産省の報告によると、特に被害の大きいアメリカでは1.3兆円、その内マネタイズ可能と期待できるのは40%の5,369億円になるとのこと。次いで中国、フランス、韓国と日本文化への関心に比例して被害額が大きくなるのは皮肉なものです。
ここで厄介のは、海外サーバと回線を伝って消費される海賊版サイトは日本の意向だけで動かせるものではないという点です。上記3サイトの閉鎖は、権利者からの申し立て、捜査当局の調査、国会および官僚関係者間での議論の末に法制化に向けて動き出し、NTTグループがこれに応じてアクセス遮断を実施したことで実現されました。
日本でサイト摘発を行う場合でもこれだけ大掛かりであることを踏まえると、各国で実施することの難しさは想像に容易いでしょう。日本の経済的機会損失を一意に解決できないところに海賊版問題の難しさがあります。
他方、海賊版サイト利用者の声には面白いヒントがあると石渡氏は言います。
海外のユーザに海賊版を使う理由をヒアリングしたところ、「自分が読みたいものが出版されない」「正規版の更新が遅い」が1、2番で、その次に「無料で読みたい 」という理由でした。他にも「進撃の巨人の最新話が自分の言語で読めるなら金は払うよ」と言われたことがあります。海賊版が強いのは事実ですが、海賊版がユーザの核心をついているのかと言われればそうではない。
特に重要なのが速度なんです。僕たちだって熱狂的に好きな作品なら100円で一日早く読めるなら出しますもんね。
Photonic System Solutionsが実施した調査によると、今の海賊版サイトは日本で出版される前よりも早く違法アップロードが確認されるとのことです。店舗に並ぶまでのどこかで流出している可能性が高いわけですが、更に電子版が普及すればそのリスクも減ります。正規版が最初に登場するのが保証されていて、かつ多言語ならば、正規版への誘導が叶って市場の正常化が達成される可能性は十分にあるでしょう。
ただし「漫画村」の事例を踏まえると、正規版の世界同時配給が海賊版を完全に撲滅することは難しいと言えます。オフェンスとディフェンスのように配給体制とサイトブロッキング体制の両輪が海賊版サイトによる被害を最小にするために必要になると石渡氏は語ってくれました。
さて、ここからは話少し変えて、マンガ特化の自動翻訳とは一体どんな技術なのかについて聞いていこうと思います。
マンガ特有の自動翻訳の難しさとは一体どこでしょうか
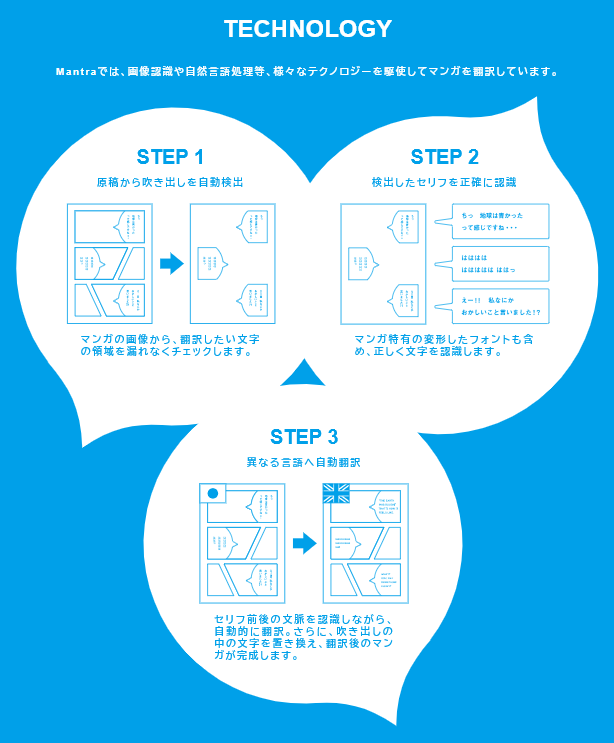
マンガは線で書かれた絵の上に、線で描かれた文字がランダムにあちこちに配置されています。読む順番もルール化できません。(同じ吹き出し内にも順番を把握して読まないといけないセリフがある)さらに、多種多様なフォントがあり、手書きで書かれているケースも多いです。マンガ専用の文字認識が必要なのはこれが理由です。
具体的にはどのようなものを作ったんですか
「文字認識」「機械翻訳」「自動写植」の3つです。読んで、翻訳して、書く。
読むことに関しては、マンガ特有のフォント変形に対応。翻訳に関しては、マンガの文脈を考慮しながら翻訳。自動写植に関しては、吹き出しにきれいに収まるようにフォントのサイズ、テキストに位置を認識しながら写植する技術です。
マンガの文字を正しく読む「文字認識」ではどこを作り込んだのでしょうか
文字認識エンジンが背景の上にある文字をたくさんみて学習すれば対応できるようになります。ただし、そのような学習データは存在しません。学習データには絵とテキストのペアが必要になるので、このペアを人工的に作りました。学習データを人工的に自動的に作る技術が肝になっています。
※上記内容は論文査読中。

「機械翻訳」では文脈を理解するのに自然言語処理を活用するんですか
画像処理と自然言語処理の両方を使用します。例えば自然言語処理でわかる文脈はテキストだけです。マンガの場合は、絵とテキストが両方混ざっています。このセリフを言っているのは誰なのか、吹き出しの順番はどうなっているのか、画像的な情報も考慮しながらじゃないと上手に翻訳できません。両方を組み合わせて初めて文脈を捉えることができます。
マンガでのセリフは言い回しが独特だったりします。そのようなものにも対応できるでしょうか
マンガの訓練データがないとマンガの翻訳が精度良くできません。マンガの英語版と日本語版を買ってきて、読み込ませると吹き出しを認識して自動で対訳テキストの集合を取り出してくる技術を作りました。これがマンガドメインの翻訳エンジンを作るためのベースとなっています。
※上記内容は国際特許出願中
日本語版と英語版を対応させること自体は複雑そうではなさそうですが、学習データ自体は参入障壁になりそうです
意外とだるいんですよね。2枚の画像を重ね合わせて取ってくるだけだと簡単なんですけど、変形されていたり、英語版だとページごと抜かれていることがあります。それをいい感じに抜き出してくる技術が翻訳エンジンを作る上では必要不可欠でした。
「自動写植」にも機械学習を活用しているのは意外でした
一般的な翻訳はテキストからテキストに変換する作業なので、普段フォントサイズは意識しません。しかしマンガでは絵から絵に変換することを求められます。フォントサイズ、どこに配置するのか、テキストボックスの縦横幅を考慮した写植する技術が必要です。そのため翻訳したテキストを組版するというのは機械学習を活用できるタスクの一つになります。
AIの種を作るための技術作りから始まって、End-to-Endの翻訳エンジンを完成させたMantra。さらには人間によるクオリティーチェック体制を簡単に構築するためのウェブのインターフェイスも自社で持つため、「マンガの翻訳」というタスクが一箇所に収納される形を取れています。
もちろん、法人向けには一度導入したらなくてはならないツールになるでしょう。しかしこれからのマンガ市場を左右するのは今だ「素人」の人たちの爆発力なのではないかと感じます。SNSで話題となり単行本化、アニメ化。小説投稿サイトからデビューといった話は今では珍しくありません。
“ 世間 ”に自分の作品の良し悪しを問いかけることが自由になったのならば、” 世界 “に問いかけるのだって自由になった方が良い。Mantraの技術を見ていて一番に感じたのはSNSが登場したときに感じた感情に少し似ていました。

最後に、このことについて聞いてみると「新しいクリエーター支援という形で、いつかサポートしたい」と力強く語ってくれました。
本当にやりたいのは、マンガの流通から言語の壁を取り払うことです。我々が読めないだけで、韓国の面白い作品だってたくさんあるでしょう。
法人を通して出てくる作品だけではなく、Webマンガでも面白い作品はたくさんあります。いつか個人向け作品のサポートをやりたい気持ちは強いです。
石渡さん、お話聞かせていただきありがとうございました。
----------[AD]----------
"それの残り" - Google ニュース
June 18, 2020 at 07:11AM
https://ift.tt/3fAMOwU
絶対に消されないブログ「dBlog」が示す、検閲耐性の重要性 - THE BRIDGE,Inc. / 株式会社THE BRIDGE
"それの残り" - Google ニュース
https://ift.tt/382YkO0
Shoes Man Tutorial
Pos News Update
Meme Update
Korean Entertainment News
Japan News Update
No comments:
Post a Comment